A week after launching it, a colleague DMed me: “it says it doesn’t know anything.”
He’d asked three questions and gotten three fallback messages. Now I had one day to figure out why it had quietly become useless.
What I built
An internal Slack bot that answers questions from our Confluence and Help Center. RAG pipeline — hybrid search over Weaviate (the vector database), then a GPT model writes the answer from the retrieved chunks. You’ve seen the diagram a hundred times.
“Hybrid search” here means two retrieval methods running side by side and their scores blended. The vector side handles “asked it in different words than the docs use” — semantic similarity. The other side is BM25, a classic keyword-ranking function: it scores documents by how often a term appears against how rare that term is across the corpus, with some normalization for document length. It’s the default lexical ranker in Lucene, Elasticsearch, and Weaviate’s hybrid mode.
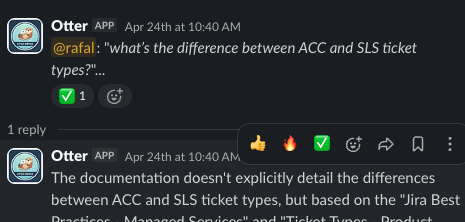
BM25 catches the cases vectors miss: project codes, acronyms, API names, anything where the literal token is the signal. The Slack example above is exactly that — “ACC” and “SLS” are short, rare tokens that embedding models happily smooth over. A pure vector search would have wandered off into “Jira tickets” generically.
I pitched it, led the build during our internal 3-day hackathon with a small team, and we won it. I kept extending it in my own time afterward. The whole stack runs in our Kubernetes cluster — the backend API, the vector database, and the reranker, all wired together with a Helm chart.
Secrets come from Vault, deployment is one CI push, daily incremental re-indexing runs on a cron. Once the plumbing was done, shipping an update took minutes. That part was never where the problems were.
The hackathon build worked well enough to demo. I tested it with a handful of easy questions. All of them passed.
Then Monday came.
The first failure: it wasn’t the model
Questions that should have worked were returning “I don’t have that information.” My instinct: the model was wrong. Maybe I need a bigger model. Maybe the embeddings are bad.
None of that was it. My GraphQL query to the vector database referenced a reranker — a small model that scores each retrieved chunk for relevance before the LLM sees it. I was using cross-encoder-ms-marco-MiniLM-L-6-v2, a lightweight cross-encoder fine-tuned on the MS MARCO passage-ranking dataset — cheap to run, noticeably better than raw vector similarity for this kind of document retrieval. But the reranker module wasn’t enabled on the collection. The query referenced something the collection didn’t have, and every request threw an exception. The error handler around it caught the failure and returned the same “I don’t have that information” fallback the bot uses for a real miss. From the user’s side it looked like the bot didn’t know anything. Underneath, the query was failing before it ever retrieved a chunk.
I was trying to debug retrieval quality. The real problem was that retrieval wasn’t happening at all.
Running one configuration script on the collection fixed it. The bot was useful the next minute.
When a RAG bot fails, it’s almost never the model. And “no results” and “bad results” look the same from the user’s side — but they’re completely different bugs. Debug the pipeline bottom-up, not top-down.
The second failure: finding the right chunks
The next wave of failures was subtler. The bot would find something, but the answer was wrong or irrelevant.
The problem: my chunks were too small (150 words) and had no context. A chunk from section 14 of a 20-section technical doc, sitting alone in the vector database, is just… text. The model has no idea what document it’s from or what it’s about.
Two fixes stacked together.
Bigger chunks. 300 words instead of 150. More context per chunk means the retrieved passage carries more of its own meaning.
Contextual retrieval. A technique Anthropic published in 2024: before indexing, a cheap model writes 2–3 sentences describing what each chunk is and where it sits in the parent document. That summary is prepended to the chunk before embedding. So a chunk that was previously “Tokens are validated via the Authorization header as Bearer tokens…” becomes “This chunk is from the ‘Authentication’ section of the API technical documentation. Key terms: Bearer token, Authorization header, token validation. Tokens are validated via the Authorization header…”
Retrieval accuracy went up sharply after this. It’s the single highest-leverage technical thing I did.
The failure nobody writes about: prompt contradictions
At this point retrieval was good and the bot was answering well — except when it flatly refused to answer questions it clearly had the context for.
I went to re-read my own prompt. 580 words. I had written it carefully. Then I read it again.
One rule said: “Never add phrases like ‘based on the documentation’.” Another rule, three paragraphs below, said: “For inferred answers, always start with ‘based on the documentation…’”
The model was averaging the two — sometimes hedging, sometimes refusing. Neither well.
I counted four more contradictions. “Answer only from the provided documents” vs “Synthesize when the documents don’t fully answer.” Two separate sections both claiming to be the highest priority. A POST-PROCESS CHECKLIST at the end telling the model to “verify” its own output — which isn’t really a thing. The model generates token by token; an instruction at the end of the prompt doesn’t make it go back and audit what it already wrote.
I rewrote the prompt from scratch. 580 words to 350. One hierarchy. No contradictions. The bot got noticeably better overnight. No model change. No retrieval change. Just removing contradictions.
Models are pattern matchers. Give them contradicting patterns and you get contradicting outputs. Prompt engineering is often just prompt editing.
What I’d tell someone starting one of these
Every “AI problem” I hit turned out to be a normal engineering problem in a new hat.
The reranker misconfiguration was a deployment problem. The tiny chunks were a data modeling problem. The contradicting prompt was a specification problem. None of them were solved by a better model.
So the model is almost never the bottleneck. Content quality is. Infrastructure is. Your prompt is. The model is the fifth thing to suspect, not the first.
Prompt compliance is probabilistic; post-processing is deterministic. I eventually added a five-line regex to normalize the bot’s output format after generation. It was infinitely more reliable than any instruction I could write. If something has to be true in the output, enforce it in code, not in prose.
And most of what I actually did to make the bot useful wasn’t model choice. It was archiving a 2021 discussion page that was polluting every result. Reformatting a runbook nobody had touched in months. Re-indexing a section the crawler had been silently skipping. The diagrams don’t show that part.
The bot isn’t perfect. It still returns “I don’t have that in my knowledge base” more often than I’d like. But the reason, most of the time, isn’t the bot — it’s that the knowledge genuinely isn’t in Confluence yet. Someone has it in their head, or in a Slack thread, or in a doc nobody ever wrote.
That turned out to be one of the unexpectedly useful things about shipping it. Every unanswered question is a prompt to go write the page that was missing. The bot quietly became a map of our documentation gaps. People use it, they hit the gaps, the gaps get filled, the bot gets smarter. That feedback loop is worth more than any model upgrade.
One of the reasons I built it the way I did was that I expected someone else would want to point the same pipeline at a different corpus. That happened — another team picked up the stack and built a customer-facing chat UI on top of it, answering customer questions from our help center articles instead of internal Confluence. Once the plumbing exists, swapping the corpus is the easy part.
Three days to build, and I’ve been making it better ever since.
Thanks for reading.