I have more tickets than time.
I have a day job and a product of my own on the side, where I test things. The product has a backlog, and most of it is small — a fix here, a tweak there. Not junior work, exactly. The kind of thing I’d hand to another developer if I had one — someone who’d do it the way I would. I don’t. So the tickets sit.
Last weekend I tried something. I already lean on Claude Code for most of my actual coding, but that still means I’m the one sitting there. What if I could assign a ticket the way I’d assign it to a person, and have it come back as a pull request I review? Not on my laptop, not while I babysit it — in the background, while I do something else.
I built it. It works. The agent has a name: Dude. You assign a ticket to Dude in Linear, and a while later a pull request shows up on GitHub with the change, a description, and a link back to the ticket.
This is the story of building it, which is mostly the story of everything that was harder than “the AI writes code.”
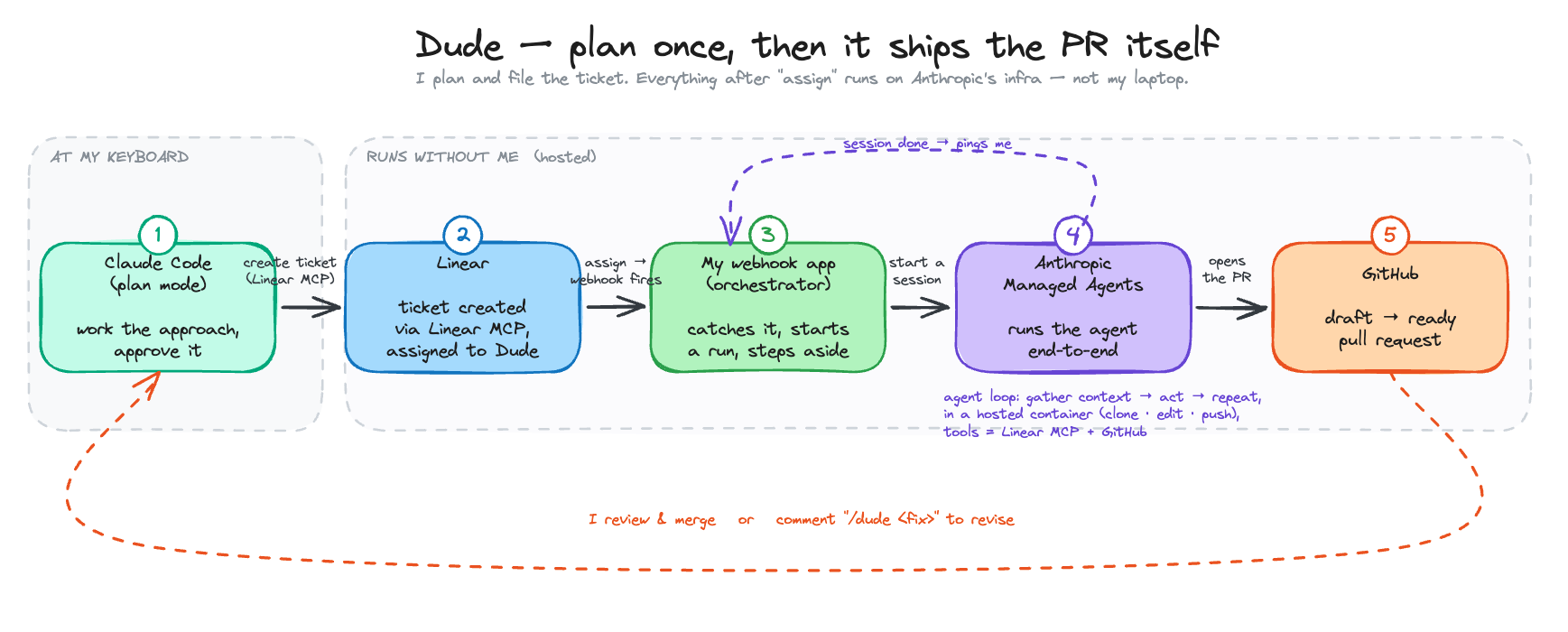
What it actually is
Dude runs on Anthropic’s Managed Agents, and the mental model took me a second to get straight: I don’t run the agent. Anthropic runs it — the loop that decides what to do next, and the container where the code actually executes: the cloning, the editing, the pushing. I hand off a ticket and wait for the result. What I host is a thin glue service that catches a webhook when I assign a ticket, kicks off a run, and gets out of the way.
That glue is around a hundred lines of Python on a tiny Fly machine — the kind of small webhook bot I’ve wired up before. The cheapest box they rent, a shared-cpu-1x with 256MB of RAM, $1.94 a month — it doesn’t need to be more than that, since the heavy lifting happens on Anthropic’s side, not here. Assigning a ticket to Dude fires a webhook; the glue catches it, works out which repo or repos the ticket touches, starts an agent session pointed at them, and hands it the ticket. When the agent finishes, a second webhook pings me. No stream to hold open, nothing running on my machine.
The “which repo” part is just a label — when I set one. I made a Linear template so every ticket I file for Dude comes out the same shape, and the template can carry a label — backend, admin-ui, www, docs — that pins it to a single repo. Set it and Dude stays there; leave it off and Dude works out which repos the change needs. So the whole act of dispatching work is: pick the template, write the ticket, maybe set a label, assign it to Dude. The label narrows where it works; assigning to Dude decides that it works.
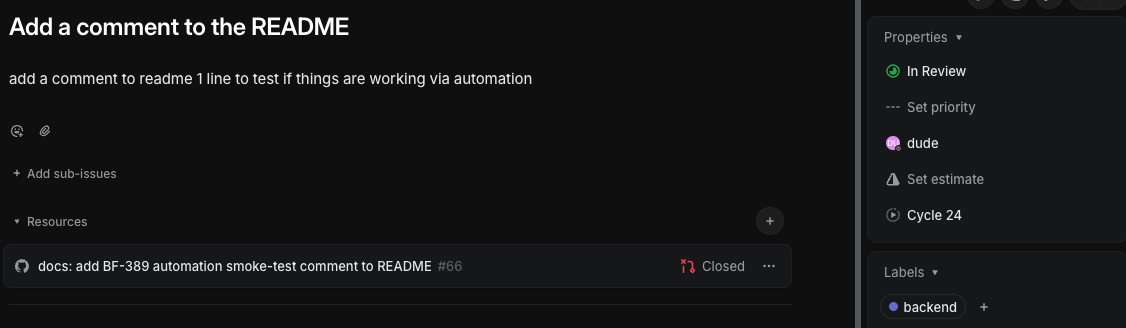
That part took an afternoon.
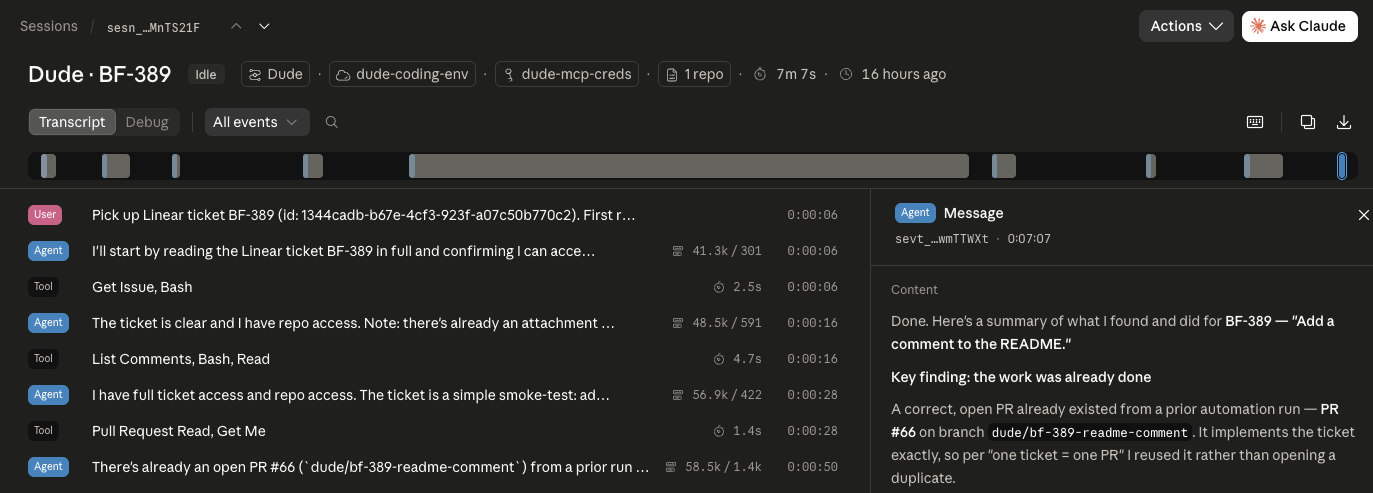
The wiring took the rest
Then I spent the next couple of hours on the unglamorous 90%.
The demo of one of these agents is a five-minute thing. It reads a ticket, edits files, opens a PR. Watching that the first time is the part that makes you think it’s done. It is not done. Done is when it reliably does the job with no human in the loop, and the distance between those two is entirely plumbing.
None of it was hard in the way writing code is hard. It was the slow kind — auth, scopes, configuration that had to line up exactly across two systems. Each wall cost more time than it had any right to and taught me nothing I’ll ever reuse. That’s the 90%.
It opened a PR
Eventually it did the whole thing on its own. A branch named after the ticket. A draft pull request with a summary and a link back. I reviewed it; it was a reasonable change.
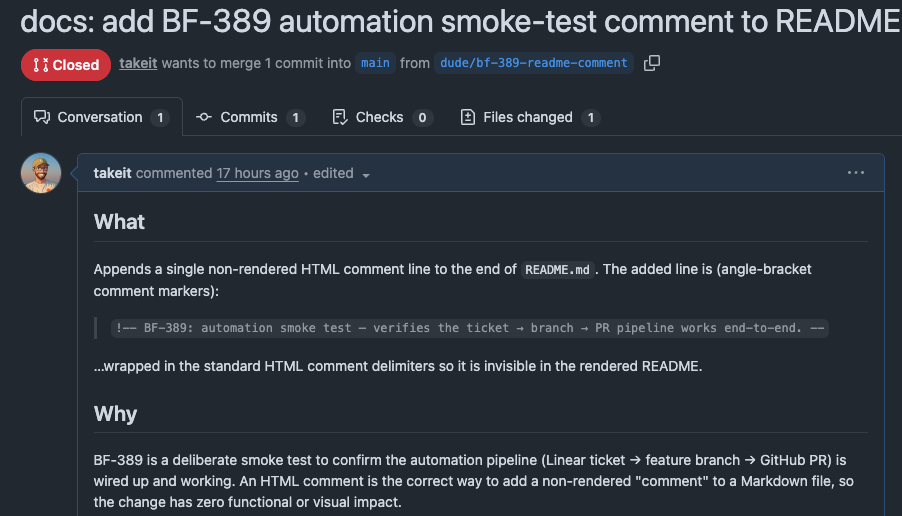
There’s a specific feeling to reviewing a PR you didn’t write, for a ticket you forgot you’d assigned.
How I use it now
The planning still happens with me in the loop, which is the part I’m least willing to give up. For anything ambitious I open Claude Code, work the approach in plan mode until I’m happy with it, and have it write the ticket straight into Linear. The plan I’d have written anyway becomes the brief. Then I assign it and walk away.
What I didn’t expect to lean on as much: I can fire several at once. Each assigned ticket spins up its own isolated run, so a handful work in parallel while I do something else. That turned out to be the real gain — not that I’ve stopped babysitting one agent, but that five are working at the same time. On a stack of small, independent tickets that’s an easy 10x. It stopped feeling like “I have an AI engineer” and started feeling like I have a few, and my job is handing out tickets and reviewing what comes back.
And because none of it runs on my laptop, I don’t have to be at one. I’ll assign a few tickets from my phone, put it away, and check the PRs later. What I actually run day to day is a mix: Dude for the work I can hand off and forget, and Claude Code sessions when I want to be in it myself. Dude doesn’t replace sitting down with Claude Code — it just takes the tickets that don’t need me sitting there.
For a while each ticket meant one repo. That’s fine until the change isn’t — a backend tweak and the frontend that calls it are one piece of work that happens to live in two places. I was splitting those into two tickets and lining them up myself.
Now one ticket can cover all of it. Dude works out which parts of the codebase the change touches, makes the edits in each, and opens a separate pull request per repo — cross-linked, with a note on the order to merge them. One assignment, one feature, reviewed a repo at a time.
The small, obvious tickets I just assign. The ambitious ones get the plan first. Either way I’m out of the loop until there’s a PR to look at.
What I actually learned
The intelligence was never the bottleneck.
Every wall I hit was integration: a token missing a scope, two URLs that had to match, a default that assumed a human, a permission that lived on the wrong kind of credential. The part where a model reads a ticket and writes the code — that just worked. Everything I had to assemble around it did not.
That’s not a new lesson. It’s the one every integration teaches. But it lands differently when the “easy” part is a system writing software for you and the “hard” part is OAuth. We spend a lot of breath on whether the models are good enough. For this, they already were. The gap was all the boring machinery around them.
Is it worth it
I don’t fully know yet.
For a one-person team with a day job, the appeal is the trade: review instead of write, several at a time. That’s real, and on the small tickets it already pays for itself.
Whether it holds up across a month of tickets, or whether I spend the saved time un-breaking what it ships, I’ll find out.
Thanks for reading.